For licensing inquiries, please contact info@grappledata.com
using a valid company/organization email address.
The AKIN Core Search/Match API was created to allow businesses and organizations to harness the power of AKIN's powerful search engine. Careful attention has been given to:
- Optimized Performance
- General ease of use
- Easy Extension
- Providing generic value indexes as well as domain optimized indexes (which will continue to expand)
AKIN's search engine uses proprietary next-generation pattern recognition algorithms to provide search that is extremely tolerant
of noise and textual variations in a way that is much more intuitive and consistent.
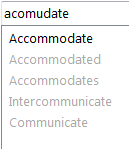
Most current search and match engines have very limited ability to deal with textual variation and noise. Additionally, many of the algorithms they use are asymmetric,
which means that if the information is fed into the compare algorithm in one way you get one result, and then if you feed the compare values into the algorithm in the
reverse order, you will get another result that can be very different from the first result. Since we never can be sure about what order
any particular kind of comparison data will be fed into a compare algorithm, this presents a significant problem in terms consistency and trustworthiness.
Products that use these algorithms try to compensate by comparing the values twice (in both directions) and then arbitrarily choosing either one or the other result based on some heuristic
that may or may not be right at any given moment. In addition to a lack of true consistency, another down side to this is that algorithmic performance is effectively cut in half.
Many of these same algorithms also suffer from the inability to intuitively judge textual/lexical similarities when text strings contain more than a little bit of variation
, distortion, and/or textual noise. When comparing their similarity measurements against the similarity assessment of human beings, these algorithms frequently produce results that are
very far away from intuitive human assessments. This results in increased user frustration and costly and time consuming customer support issues that are generally never resolved.
AKIN does much better. From the ground up, AKIN's algorithms have been designed to be symmetric without sacrificing performance. Regardless of what order you feed the values into
the AKIN match algorithms you will get exactly the same or extremely similar results. Also, AKIN has been carefully engineered to produce textual similarity assessment scores that
much more closely emulate how humans assess textual similarities. AKIN can see through extremely noisy text containing distortions and variations and see the similarities when
other search engines simply choke.

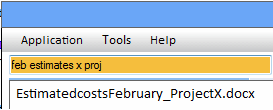
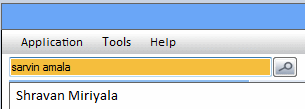
The awesome power of AKIN's advanced fuzzy pattern recognition engine combined with domain specific knowledge bases enables several semantically aware features that
frequently feel like magic, when AKIN is able to intuit the meaning of what you type and provide early discovery of most relevant content without having to visually scan through
a document or try numerous combinations of possible search terms manually.
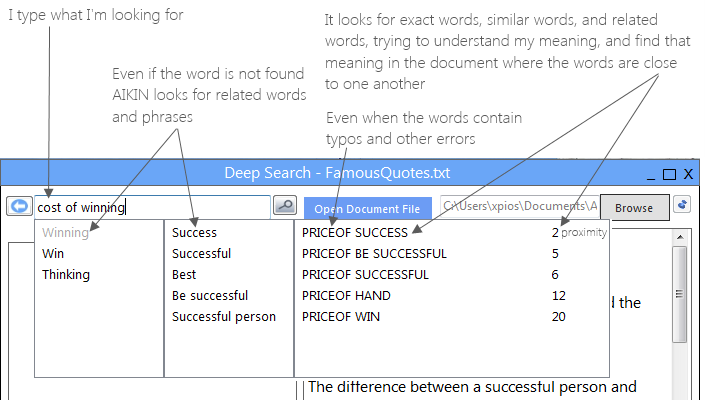
The following are the types of indexes and functionality the API currently provides, as well as their general usage:
- Generic Lookup Value Index
This index is used when you have a set of textual values that you need to be able to lookup in a non-exact fuzzy way
with a high degree of tolerance, performance, and accuracy. Normally, this is used for things like taxonomies, where you have a set of values that are
unique and standardized.
A good example of a value set would be the names of states or cities. This index can be used for high performance data cleansing and standardization operations to quickly
find mispelled or distorted words and replace them with the correct standardized value.
Additionally, you might use this index when a user enters values onto a field in
one of your applications. You can query this index in real-time providing the user with immediate suggestions while they are typing. AKIN's advanced pattern recognition
will overcome most mispellings and can accurately assess similarity even when the query text is very different.
- Record Field Value Index
This index is used for fuzzy lookup of short to medium length values (1 to 200 characters generally with no actual limit),
and was designed to receive values from specific records within a data set. When inputing text values into this index, you specify
what we call a Composite Identity for the value consisting of:
- Record ID
- List of Field IDs (optional)
- Domain ID (optional)
- Document ID (optional)
When you search the index, each result in the set of results returned to you will have its original Composite Identity so that you can easily identify the exact records, fields, and/or documents
the results were found associated with.
- Paragraph or Document Index
This index has been optimized for fast fuzzy lookup of larger chunks of text values or whole documents. Like the "Record Field Value Index" above, this index also receives values along
with a Composite Identity which allows you to identity specific documents, records, and/or fields that the value originated in when results are returned to you.
- Semantics-Aware Deep Fuzzy Document Searcher
While the Paragraph or Document Index above is used to find specific documents out of a larger set of documents using fuzzy search,
the Fuzzy Document Searcher class is used to provide deep discovery information within the content and context of a single document.
The user or system passes the FDS a set of document text, and then can make iterative queries against the text using both fuzzy logic,
as well as our semantics-aware early discovery methods to find information in large chunk result sets or small discrete sets on demand.
- People Name Index
This index has been optimized to work with the specific domain of people's names. A unique set of First and/or Last names
, as well as First Name or Nick Name variations are provided to the index for indexing. Then the index can be queried for fast lookup of names. Additionally, when
indexing values, you can specify whether the specific name being input is a more significant or relevant name (e.g. such as a known contact),
and when querying those names will be given more relevance in returned result sets.
This index is useful in applications where users may be typing in names on forms and you want to help them find names quickly (e.g. finding names of important customers),
or when doing data cleansing operations
over data that may be spelled incorrectly or have variations that you want to standardize.
Below, we will share with you some deeper technical specifics, as well as provide you with code samples to demonstrate how easy it is to use in your projects, and the types of results
you can expect.
Currently, this API is available as a Microsoft .Net 4.5.1 assembly.
The API consists of a component class called "SearchIndexManager". This component plays well with constructor-based Dependency Injection Frameworks. All indexes are loaded and managed within the manager in memory. Thus, these are all "In-Memory" indexes,
and the size limitations of any specific index will depend on the amount of memory available. These indexes have been optimized to use as little memory as possible, and also
provide post indexing operations to optimize space after a large indexing batch job has completed.
Serialization and Deserialization of indexes is provided by the API. You must hand the API a Stream object when Serializing or Deserializing indexes, which means that the API
is flexible to many different hosting environments and lets you handle where that stream actually gets saved (other memory objects, on disk, in the cloud, etc.).
The Generic Lookup Value and People Name indexes are single threaded indexing processes. However, the Record Field Value and Paragraph or Document indexes
both provide multi-threaded and high volume batch oriented methods of indexing. Internally, each index is optimized to use multi-threading for lookup operations as is necessary
and warranted for the specific lookup operation and the number of CPU's available.
Using the API is very simple. In the example below we show how to perform the following operations in C# code:
- Create indexes
- Add values to indexes
- Search indexes
- Delete indexes
- Serialize & Deserialize indexes
Although we do not show examples for each index type, the example shows the general pattern used for each index type. Many more
examples can be viewed in our comprehensive documentation and/or demonstrations once a request for licensing information
has been submitted and approved.
As demonstrated above, the process of using the indexes is straightforward and simple, yet provides powerful performance and accuracy. To get a
good idea of how fast and accurate this API is, you can download and try out our AKIN Desktop HyperSearch product.
For more information please feel free to contact us at
info@grappledata.com